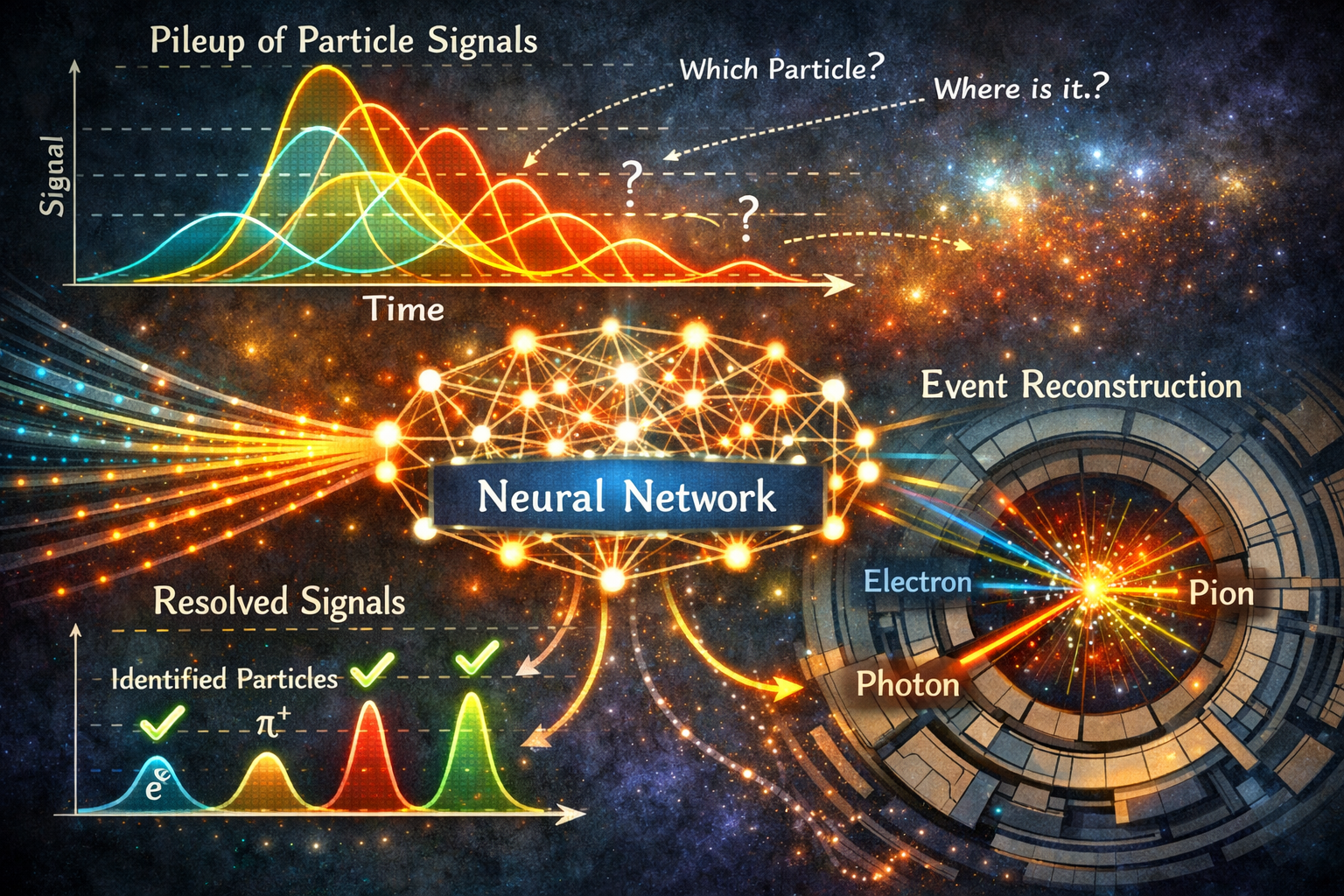
About the Project
SPARTAN (SPace pARTicle trAcking with Neural-networks) is a PNRR-funded project that developed an innovative machine-learning-based system for tracking charged particles in space applications. By combining Graph Neural Networks, 2D Convolutional Neural Networks, and FPGA-based real-time inference, the project demonstrated the feasibility of intelligent on-board processing for future space missions under strict power and reliability constraints.

Introduction: Particle Trackers and the Pile-Up Challenge
Particle trackers are essential instruments in high-energy physics and astrophysics. Whether they rely on scintillating fibers, silicon strips, or pixel arrays, their purpose is the same: to measure the position, momentum, and trajectory of charged particles as they pass through a sensitive medium. Space missions such as the Fermi Gamma-ray Space Telescope and the Alpha Magnetic Spectrometer (AMS-02) aboard the International Space Station depend on these instruments to study cosmic rays, gamma rays, and antimatter directly in orbit.
Reconstructing particle tracks from the raw signals produced by a detector has traditionally relied on geometric and physics-based algorithms. These methods work well under moderate conditions, but they degrade significantly in high-rate environments, where the phenomenon known as pile-up — the superposition of signals from multiple simultaneous or near-simultaneous particles — makes it extremely difficult to separate individual tracks. As particle rates grow, these classical algorithms become computationally prohibitive, and on a satellite, where available power is measured in watts rather than kilowatts, this represents a fundamental bottleneck that limits what can be done on board.
The SPARTAN project set out to address precisely this challenge. Funded under the Italian PNRR – Missione 4, Componente 2 (Dalla ricerca all’impresa), Spoke 3 of the ICSC National Centre for HPC, Big Data and Quantum Computing, the project explored whether modern machine learning techniques could offer a viable alternative to classical track reconstruction, and whether such algorithms could be deployed efficiently on space-grade programmable hardware.
Schematic representation of a multi-plane particle tracker. Charged particles crossing several detection layers leave a sequence of hits that must be associated into tracks.
Schematic representation of a multi-plane particle tracker. Charged particles crossing several detection layers leave a sequence of hits that must be associated into tracks.
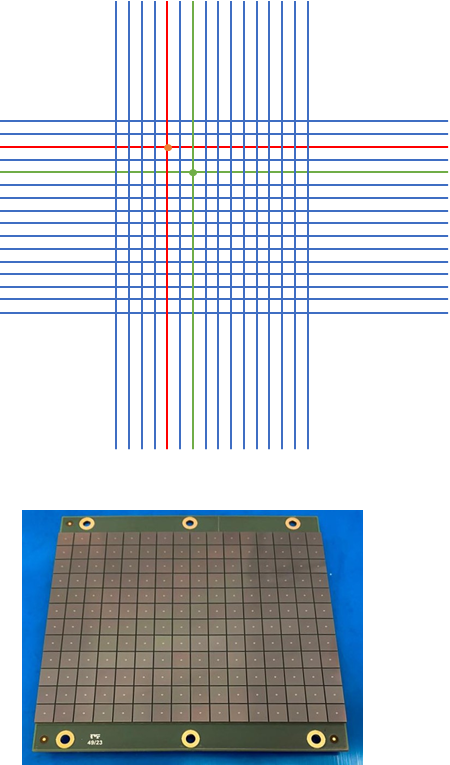
The scintillating fiber tracker of the Ziré instrument aboard the NUSES space mission, one of the primary real-world targets for the SPARTAN algorithms.
The scintillating fiber tracker of the Ziré instrument aboard the NUSES space mission, one of the primary real-world targets for the SPARTAN algorithms.
Project Objectives and Scope
SPARTAN was conceived as a tightly integrated project in which algorithmic development, hardware implementation, and experimental validation would proceed in parallel rather than sequentially. The overarching goal was not a purely theoretical demonstration but a concrete assessment of the real-world feasibility of ML-based tracking solutions for space applications, evaluated against hard constraints of power consumption, latency, and reliability.
The project articulated its work across seven interconnected work packages. The first two (WP1 and WP2) focused on dataset generation and algorithm development: starting from synthetic data produced with the GEANT4 particle physics simulation framework, the team progressively moved toward more realistic scenarios including curved tracks in magnetic fields and, crucially, the addition of timing information. The third and fourth work packages (WP3 and WP4) addressed the FPGA implementation, targeting the Xilinx Versal and Zynq Ultrascale+ families, and included the development of a complete firmware and software framework for real-time data exchange. WP5 extended the validation to experimental datasets collected from ground-based test setups and from data acquired with the Ziré tracker of the NUSES mission. WP6 evaluated the state of the art in front-end electronics — including SiPM arrays, the Weeroc Radioroc ASIC, and the CERN PicoTDC — to understand how current technology limitations affect the quality of timing measurements available to the neural network. Finally, WP7 performed a systemic analysis of whether the proposed architecture is truly viable for a future space mission, accounting for power budgets, radiation tolerance, and scalability to detectors with thousands of channels.
The introduction of picosecond-level timing information was a distinctive ambition of the project. By using the CERN PicoTDC, which Nuclear Instruments had already employed in previous readout solutions, the project aimed to reach timing resolutions of tens of picoseconds, adding a temporal dimension to the spatial hit pattern and enabling the network to distinguish between nearly simultaneous overlapping tracks that spatial information alone cannot resolve.
Machine Learning Approach
Graph Neural Networks for Track Reconstruction
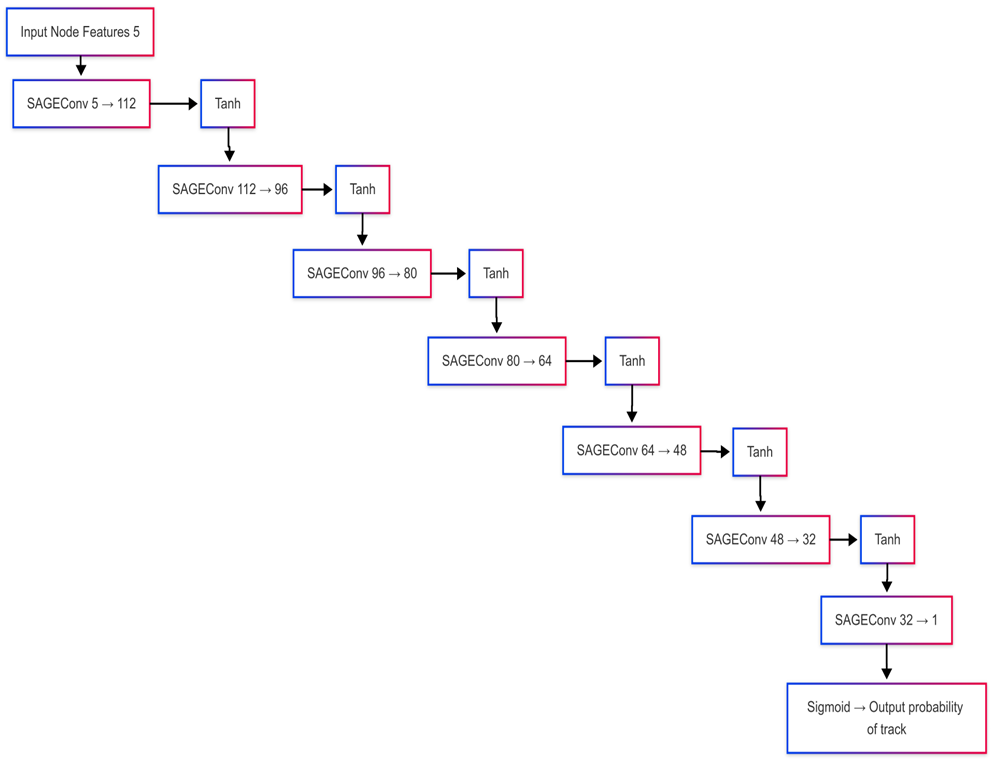
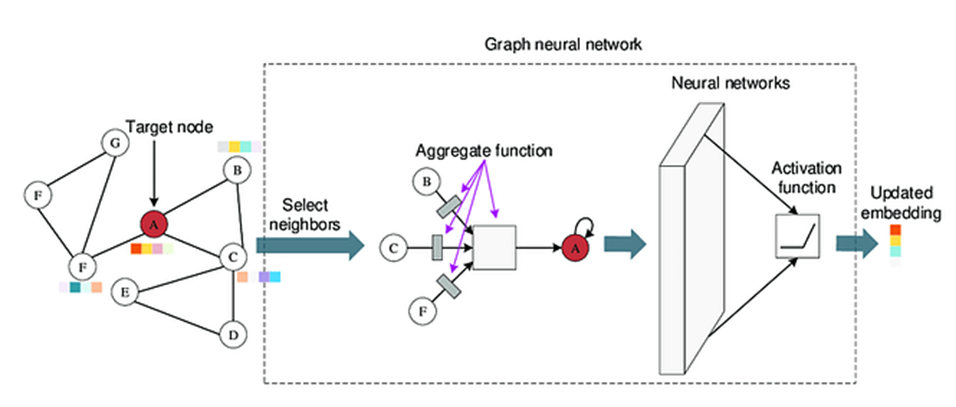
The primary algorithmic tool developed in SPARTAN is a Graph Neural Network (GNN). GNNs are inherently well-suited to the track reconstruction problem because they represent detector hits as nodes in a graph and potential track segments as edges between them, allowing the network to reason directly about spatial relationships across multiple detection planes. The architecture chosen is based on SAGEConv (GraphSAGE) convolution layers, which aggregate information from local neighbourhoods of nodes in a way that scales effectively to large hit multiplicities.
The GNN was developed in Python using PyTorch Geometric, starting from toy datasets and progressively moving to more realistic scenarios produced by GEANT4. In each training configuration, the network receives as input the coordinates of all hits detected across the tracker planes, together with their associated charge and — in the timing-enhanced variants — their time-of-arrival, and produces a classification of which hits belong to the same track. The training set was carefully constructed to include a range of pile-up conditions, noise hits, and detector inefficiencies, ensuring that the model would generalise to real experimental data rather than overfitting to idealised conditions.
Tests on data from the Ziré test beam confirmed that the GNN achieves excellent track reconstruction accuracy even in high-occupancy conditions, outperforming the classical geometric approaches in terms of robustness to pile-up.
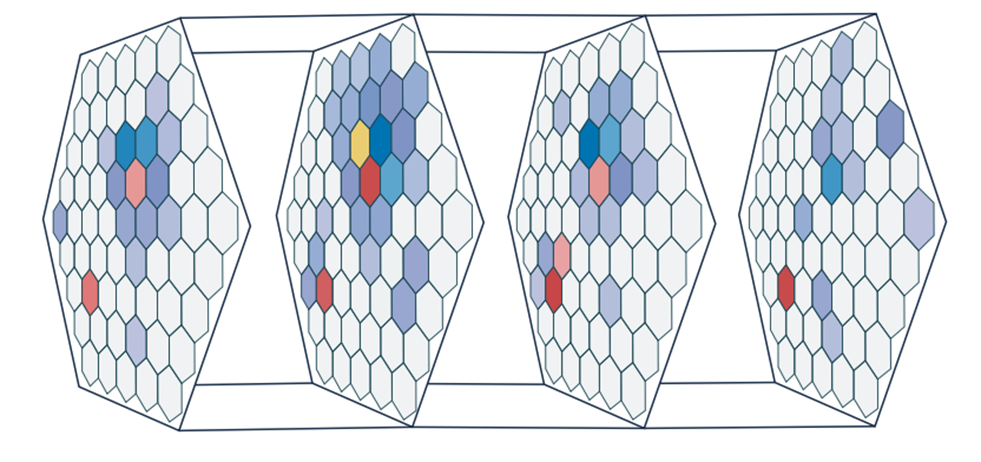
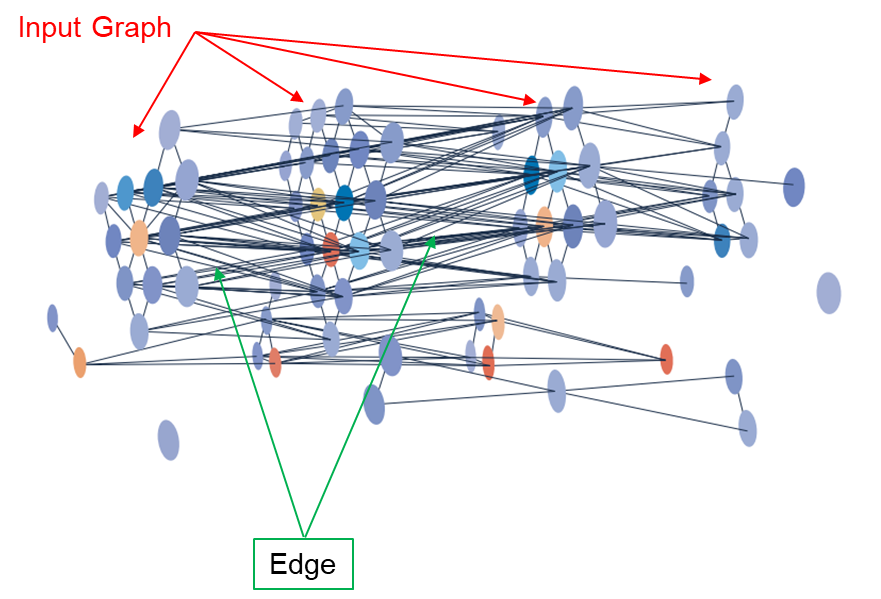
Example of a graph representation of detector hits: each node corresponds to a hit on a detection plane, and edges encode potential track segment hypotheses.
Example of a graph representation of detector hits: each node corresponds to a hit on a detection plane, and edges encode potential track segment hypotheses.
Graph structure after edge filtering: the GNN assigns weights to edges based on their likelihood of belonging to the same track, enabling clean track separation even under pile-up conditions.
Graph structure after edge filtering: the GNN assigns weights to edges based on their likelihood of belonging to the same track, enabling clean track separation even under pile-up conditions.
The SAGEConv operation: each node aggregates feature vectors from its neighbours, iteratively building a global representation of the graph that captures long-range spatial correlations between hits.
The SAGEConv operation: each node aggregates feature vectors from its neighbours, iteratively building a global representation of the graph that captures long-range spatial correlations between hits.
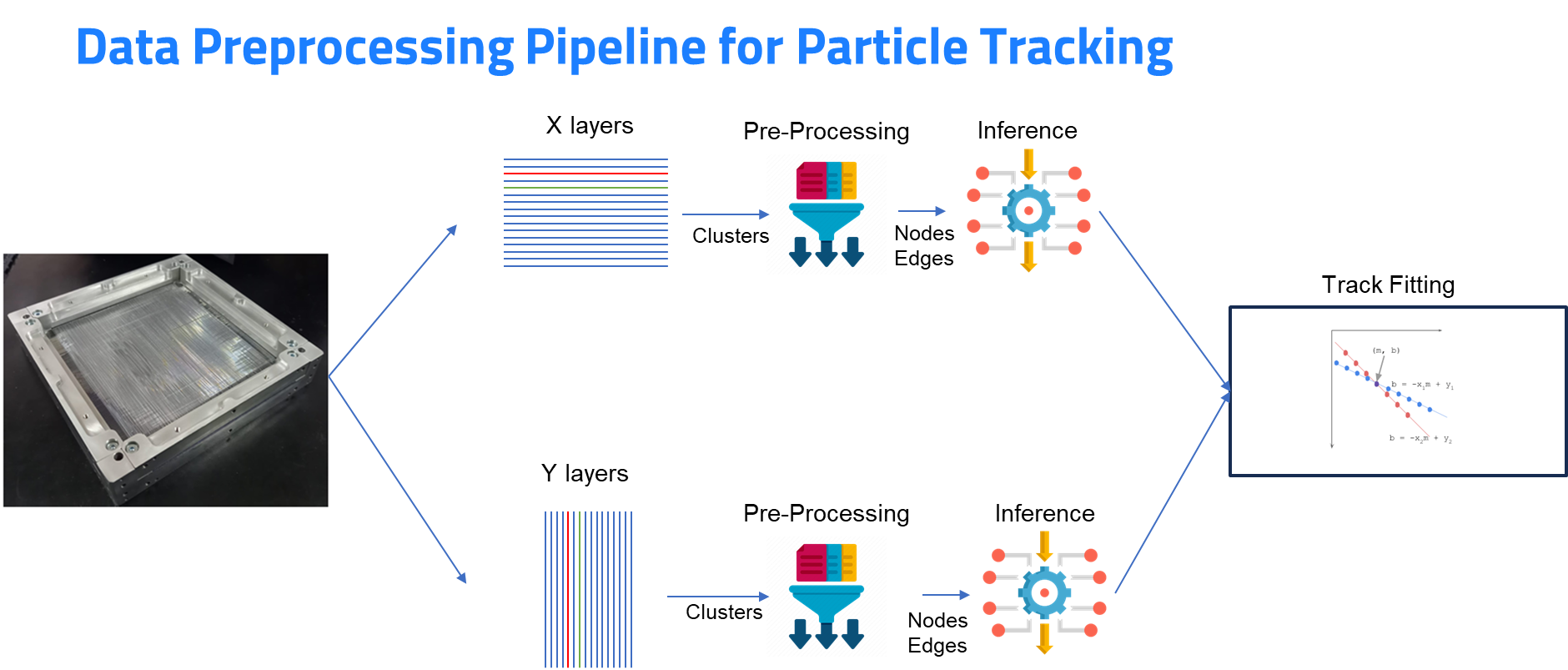
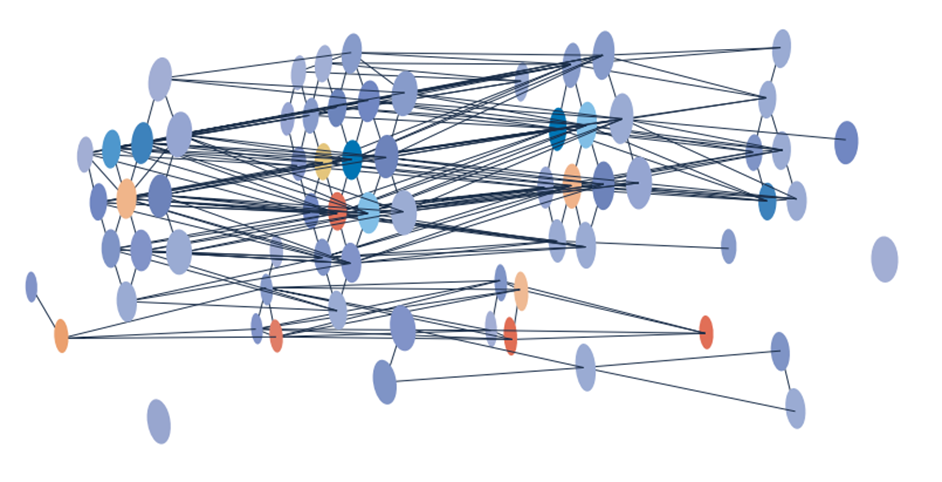
End-to-end inference pipeline of the GNN: from raw detector hits to reconstructed track candidates, including the embedding, message-passing, and edge-classification stages.
End-to-end inference pipeline of the GNN: from raw detector hits to reconstructed track candidates, including the embedding, message-passing, and edge-classification stages.
Architecture of the complete GNN model used for track reconstruction, showing the sequence of GraphSAGE message-passing layers followed by the edge classification head.
Architecture of the complete GNN model used for track reconstruction, showing the sequence of GraphSAGE message-passing layers followed by the edge classification head.
Track reconstruction output of the GNN on a simulated multi-track event: correctly associated hits are shown by colour, demonstrating effective pile-up resolution.
Track reconstruction output of the GNN on a simulated multi-track event: correctly associated hits are shown by colour, demonstrating effective pile-up resolution.
2D Convolutional Neural Networks for FPGA Deployment
While the GNN delivers superior accuracy, its graph-based computation is inherently irregular and difficult to pipeline efficiently on FPGAs. An alternative architecture was therefore developed in parallel: a 2D Convolutional Neural Network (CNN2D) operating on 32×32 binary images derived from the detector hit patterns. By mapping the multi-plane hit occupancy onto a two-dimensional pixel grid, the problem is recast in a form that is directly amenable to standard convolutional operations, which are both well understood and efficiently implemented on programmable logic.
The CNN2D was developed as a progressively refined model, starting from a simple toy prototype and converging toward an architecture optimised for deployment via HLS4ML (High-Level Synthesis for Machine Learning). HLS4ML translates trained neural networks described in Python/Keras directly into synthesisable HDL code, enabling low-latency FPGA inference without manual firmware development. This approach was compared against the alternative Xilinx DPU (Deep Processing Unit) soft-core, which offers greater flexibility at the cost of lower efficiency. The HLS4ML-based solution proved superior for the compact CNN2D architecture, delivering excellent power–performance trade-offs.
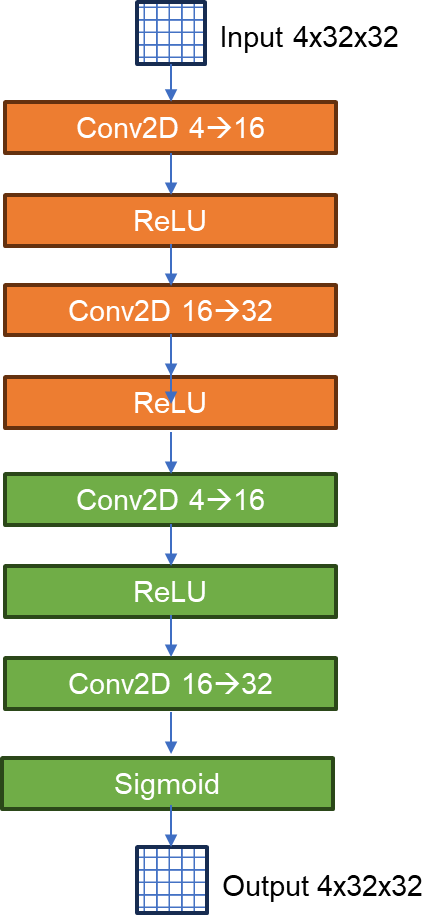
Architecture of the CNN2D model: the network processes 32×32 images of detector occupancy maps, extracting spatial features through successive convolutional and pooling layers before producing a track classification output.
Architecture of the CNN2D model: the network processes 32×32 images of detector occupancy maps, extracting spatial features through successive convolutional and pooling layers before producing a track classification output.
Visual comparison between the raw 32×32 input occupancy map (left) and the network’s output classification (right), demonstrating how the CNN2D separates tracks in a pile-up scenario.
Visual comparison between the raw 32×32 input occupancy map (left) and the network’s output classification (right), demonstrating how the CNN2D separates tracks in a pile-up scenario.

Performance curves of the CNN2D model as a function of pile-up multiplicity, showing accuracy, purity, and efficiency metrics for both the software reference and the FPGA-deployed version.
Performance curves of the CNN2D model as a function of pile-up multiplicity, showing accuracy, purity, and efficiency metrics for both the software reference and the FPGA-deployed version.
Hardware Architecture
Hybrid FPGA + NPU System
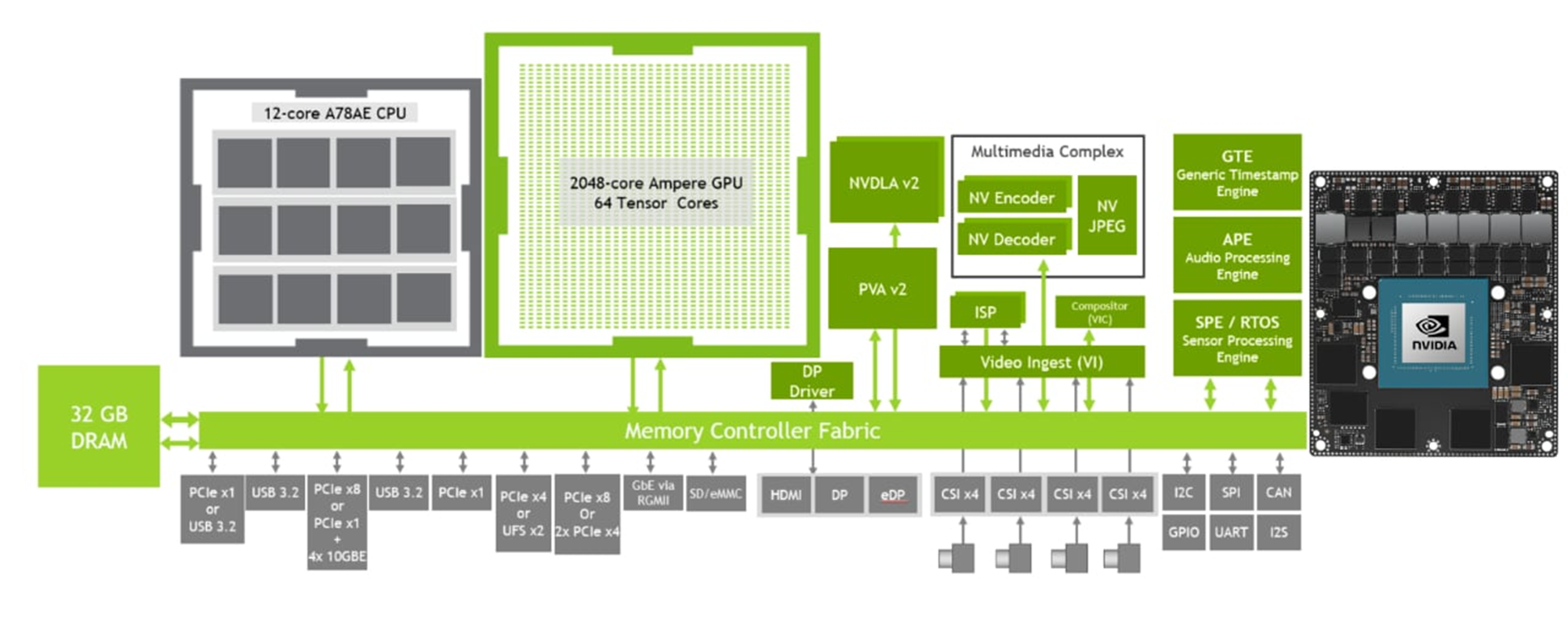
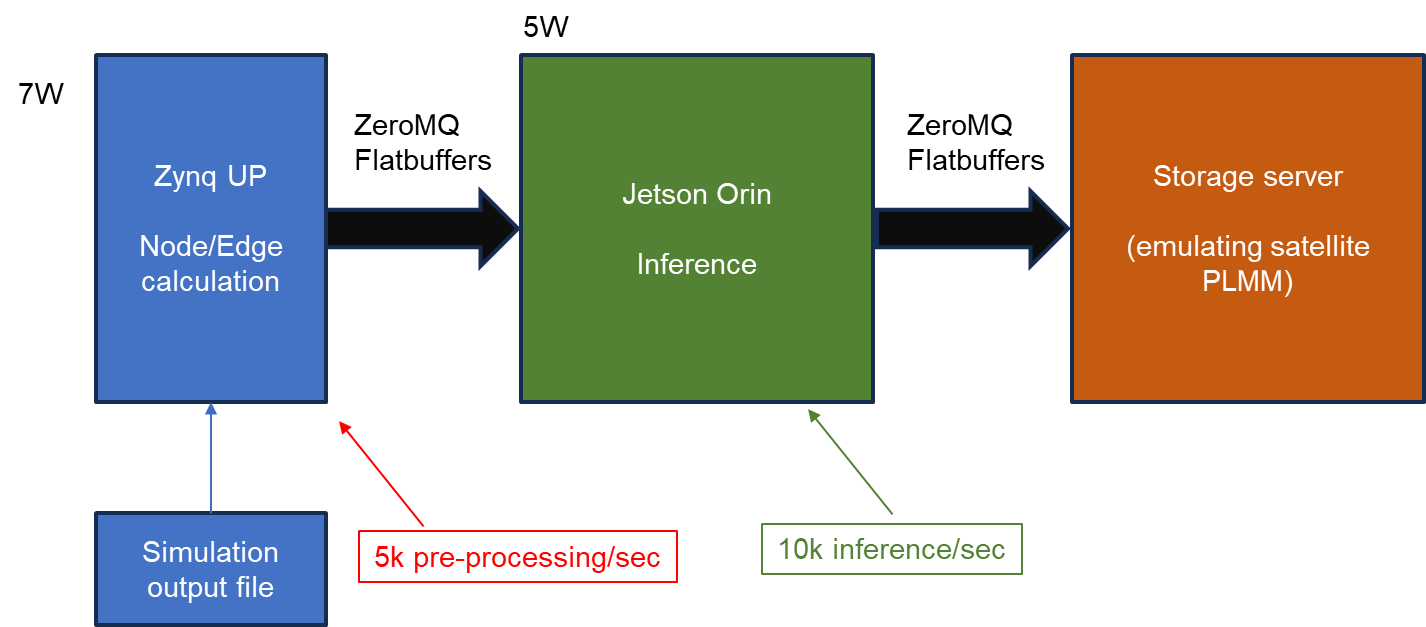
A central finding of the project was the definition of the optimal hardware architecture to support real-time ML inference. After an in-depth analysis of the available options, a hybrid architecture was chosen that exploits the complementary strengths of two components. A Zynq Ultrascale+ FPGA acts as the data concentrator and pre-processor: it receives the raw digital signals from the front-end ASICs (Citiroc-based acquisition boards), performs clustering and zero-suppression, builds events, and feeds the processed data to the inference engine. The GNN inference itself is offloaded to an NVIDIA Jetson Orin NPU, which provides dedicated hardware support for the irregular graph operations at power levels well below those of a conventional GPU.
Measurements on this system showed that the Jetson Orin NPU can execute the full GNN inference pipeline with a power consumption below 4 W, while sustaining throughput of tens of thousands of tracks per second. This performance level is remarkable given the complexity of the algorithm, but the use of a commercial NPU device that has not undergone space qualification represents a significant limitation for mission-critical applications. Radiation-tolerant versions of such devices are not currently available, making this solution appropriate for ground-based or commercially hosted missions, but not yet for scientific satellites in high-radiation orbits.
Block diagram of the hybrid FPGA + Jetson Orin architecture: the Zynq Ultrascale+ handles front-end data concentration and pre-processing, while the Jetson Orin NPU executes the GNN inference.
Block diagram of the hybrid FPGA + Jetson Orin architecture: the Zynq Ultrascale+ handles front-end data concentration and pre-processing, while the Jetson Orin NPU executes the GNN inference.
The complete inference system assembled for laboratory testing, showing the Zynq-based concentrator board and the Jetson Orin module interfaced via high-speed serial links.
The complete inference system assembled for laboratory testing, showing the Zynq-based concentrator board and the Jetson Orin module interfaced via high-speed serial links.
CNN2D on FPGA via HLS4ML: The Space-Compatible Path
For applications that require space qualification, the CNN2D implementation on FPGA via HLS4ML represents the viable path. Deployed on the Zynq Ultrascale+ that serves as the data concentrator, the CNN2D adds only approximately 1 W of additional power dissipation to the system — a figure that is fully compatible with the power budgets of orbital instruments. The latency per event is similarly modest, enabling real-time processing without buffering delays that would compromise the trigger chain.
The Zynq Ultrascale+ is commercially available in Military Grade and Space Grade versions with documented radiation tolerance, making this architecture directly extensible to future space missions. The HLS4ML-generated firmware is also inherently maintainable and re-trainable: should the detector geometry or particle environment change, the model can be retrained offline and re-synthesised without redesigning the hardware.


Left: comparative benchmark of inference throughput and power consumption across CPU, GPU, and Jetson Orin NPU platforms — the Jetson Orin achieves the best performance-per-watt ratio for GNN inference. Right: the Zynq Ultrascale+ evaluation board used for CNN2D deployment via HLS4ML, available in Military and Space Grade versions for space-qualified missions.
Experimental Setup and Validation
The experimental validation of the full system was carried out through a series of progressive test campaigns. The front-end acquisition chain is built around Citiroc ASIC-based readout boards, which digitise the SiPM signals from the scintillating fiber layers and transmit them to the Zynq concentrator via high-speed serial links. Dedicated firmware was developed for the concentrator to handle event building, trigger management, and the simulation of realistic temporal data streams including programmable occupancy levels.
In the first validation phase, a precision pulser was used to inject calibrated signals mimicking particle hits into the detector channels. This allowed the full electronic chain — from acquisition through clustering to ML inference — to be characterised under controlled conditions and confirmed that no data was lost during continuous high-rate operation. The clustering algorithm running on the concentrator proved essential to this result: by grouping adjacent hits into compact cluster descriptors before passing them to the neural network, it reduced the data volume by more than an order of magnitude, making real-time inference tractable.
The second validation phase used datasets collected with actual scintillating fiber detector planes, including data from test beam campaigns on the Ziré tracker of the NUSES mission. These data provided the most realistic test of the algorithm’s performance, including genuine detector noise, channel-by-channel response variations, and the non-ideal timing characteristics of real front-end electronics. Both the GNN and the CNN2D were trained and evaluated on this data, confirming that the performance observed on simulated datasets was reproducible under real experimental conditions.
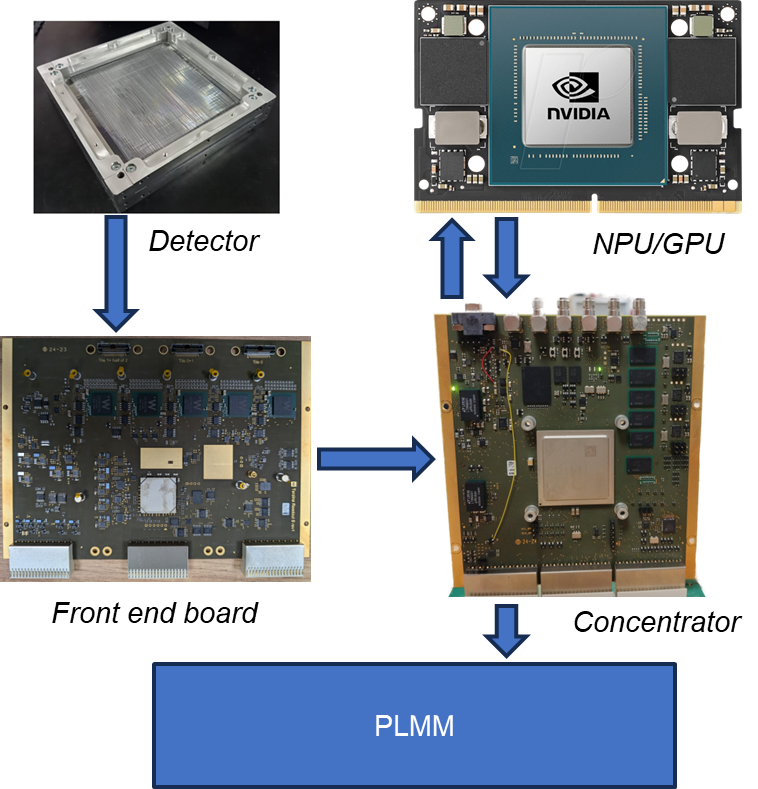
The experimental validation setup: Citiroc-based acquisition boards (left) connected to the Zynq Ultrascale+ concentrator (right), with the full ML inference pipeline running in real time on data acquired from scintillating fiber detector planes.
The experimental validation setup: Citiroc-based acquisition boards (left) connected to the Zynq Ultrascale+ concentrator (right), with the full ML inference pipeline running in real time on data acquired from scintillating fiber detector planes.
Results and Assessment for Space Applications
The results of SPARTAN draw a clear and technically grounded picture of where ML-based particle tracking stands today with respect to space deployment.
Graph Neural Networks offer the highest reconstruction accuracy and the greatest flexibility in handling irregular hit patterns and complex pile-up configurations. However, their irregular computational graph makes full FPGA implementation impractical at the current state of the art. The most viable path for GNN inference is the hybrid architecture with the Jetson Orin NPU, which achieves sub-4 W operation and high throughput. For ground-based experiments and commercially hosted space platforms that do not require radiation-hardened components, this architecture is immediately usable.
2D Convolutional Neural Networks deployed on FPGA via HLS4ML offer a performance level that is somewhat lower than GNN but fully adequate for many tracking scenarios, particularly when the detector geometry can be mapped onto a regular grid. The power overhead of approximately 1 W on the Zynq Ultrascale+ is negligible from a systems perspective, and the availability of the Zynq family in Military and Space Grade versions makes this solution directly compatible with future scientific satellite missions. This represents the most concrete and near-term path toward deploying neural network tracking on board an orbital detector.
The evaluation of front-end electronics performed in WP6 confirmed that the CERN PicoTDC and Weeroc Radioroc ASICs can provide timing resolutions in the range of tens of picoseconds, sufficient to add meaningful temporal information to the track reconstruction. The challenge lies not in the measurement resolution per se, but in ensuring that the propagation of timing data through the readout chain preserves this precision, a requirement that constrains the architecture of future detectors that wish to exploit 4D tracking.
The systemic analysis of WP7 concluded that, at the current state of technology, a space-grade particle tracking system based on ML inference is feasible for detectors with hundreds to low thousands of channels, operating at the power levels typical of small to medium satellite payloads. Scaling to larger trackers will require advances in FPGA capacity and in the space qualification of neural processing units.
Impact and Future Directions
SPARTAN has delivered concrete and measurable outcomes on multiple dimensions. From the scientific perspective, the project has demonstrated for the first time in a rigorous experimental setting that ML-based track reconstruction can match or exceed the performance of classical algorithms in conditions of high pile-up, while consuming power compatible with satellite operation. This result opens the door to a new generation of onboard data reduction systems that can significantly increase the scientific throughput of space missions without requiring a proportional increase in downlink bandwidth.
For Nuclear Instruments, the project has built a strategic competence base at the intersection of machine learning, FPGA firmware engineering, and space electronics — an area of growing importance both for scientific missions and for commercial space applications. The expertise in HLS4ML deployment, in particular, represents a differentiating capability that can be applied to a wide range of future projects beyond particle tracking, including gamma-ray telescope trigger systems, PET scanner reconstruction engines, and real-time classification in high-rate scintillation detectors.
The connection between SPARTAN and the broader research ecosystem was strengthened through the use of data from the NUSES/Ziré mission and the participation in the ICSC framework. The algorithms and hardware architectures developed in this project are directly applicable to future payloads under study within the Italian space physics community, including the proposed AMS100 magnetic spectrometer.
The methodologies developed for applying timing information to track disambiguation also have direct relevance to medical imaging: the 4D tracking approach explored in SPARTAN shares fundamental principles with Time-of-Flight PET (TOF-PET) reconstruction, where combining spatial and temporal correlations allows for sharper images at lower patient dose. This cross-disciplinary applicability reinforces the broader impact of the research.
The scintillating fiber tracker assembly used in the final experimental validation campaign, equipped with SiPM readout and Citiroc-based front-end electronics.
The scintillating fiber tracker assembly used in the final experimental validation campaign, equipped with SiPM readout and Citiroc-based front-end electronics.